
동작 중의 자연 언어 처리:PythonSummaryNaturalLanguageProcessinginAction에서 텍스트를 이해, 분석, 생성하는 것은 NLP와 AI전용 패키지의 생태계에서 Python의 힘을 이용해서 인간의 언어를 이해하는 머신을 만들기 위한 가이드입니다.이 프린트 북의 구입에는 Manning Publica에서 PDF, Kindle및 ePub형식의 무료 eBook이 포함되어 있습니다···www.amazon.com
본 소개인의 언어를 읽고 해석할 수 있는 프로그램을 만들려는 모든 개발자를 위한 지침서다.바로 쓸 수 있는 파이썬 패키지를 이용하여 텍스트의 의미를 포착하고 이에 응하고 반응하는 채팅 봇을 구축한다.또 전통적인 NLP접근은 물론, 보다 최근의 심층 학습 알고리즘과 텍스트 생성 방법을 동원하고 날짜와 이름 추출, 텍스트 작성, 비정형 질문에 대한 응답 등 많은 실질적인 NLP문제를 해결한다.
인기글


![[모고]2018학년도 6월 고3 모의고사 DNS스푸핑 기술 지문 분석](https://mblogthumb-phinf.pstatic.net/MjAxNzA2MDFfMjIg/MDAxNDk2Mjk2OTIyNDQ1.zqxfcVI0GPe6PpkyMYVNTmCWoPnP15xibbjR0w0glAUg.M1guhN4niAGzq8qC3xnQrrS9eVLWoxDzKnaAgTe4Vqwg.PNG.pjseong01/2.png?type=w800 "[모고]2018학년도 6월 고3 모의고사 DNS스푸핑 기술 지문 분석")


본 소개인의 언어를 읽고 해석할 수 있는 프로그램을 만들고자 하는 모든 개발자를 위한 지침서다. 바로 사용할 수 있는 파이썬 패키지를 이용해 텍스트의 의미를 포착하고 그에 따라 반응하는 챗봇을 구축한다. 또한 전통적인 NLP 접근법은 물론 보다 최근의 심층 학습 알고리즘과 텍스트 생성 기법을 동원하여 날짜와 이름 추출, 텍스트 작성, 비정형 질문에 대한 응답 등 많은 실질적인 NLP 문제를 해결한다.

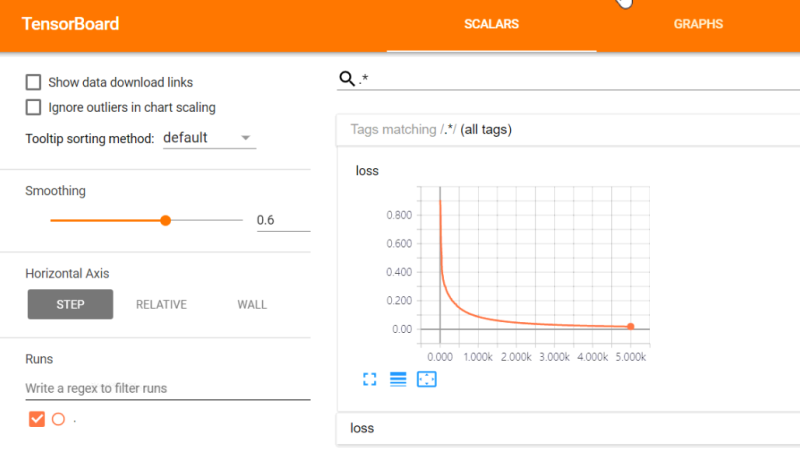
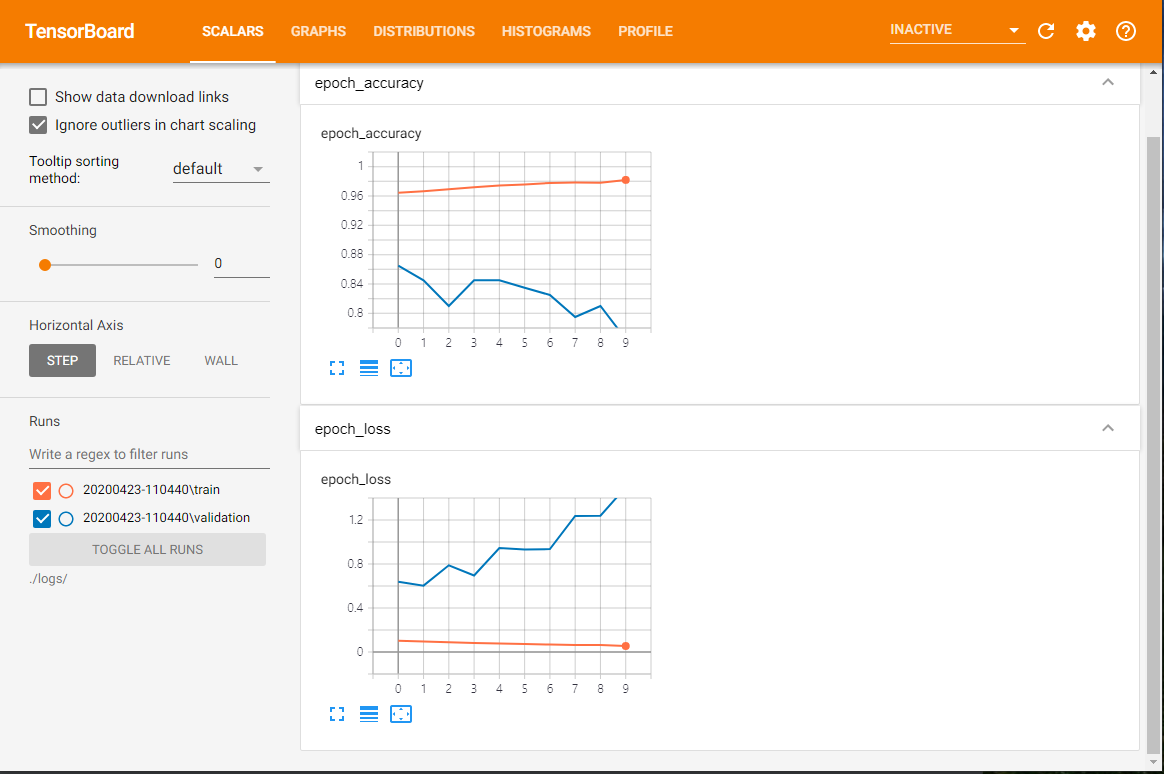
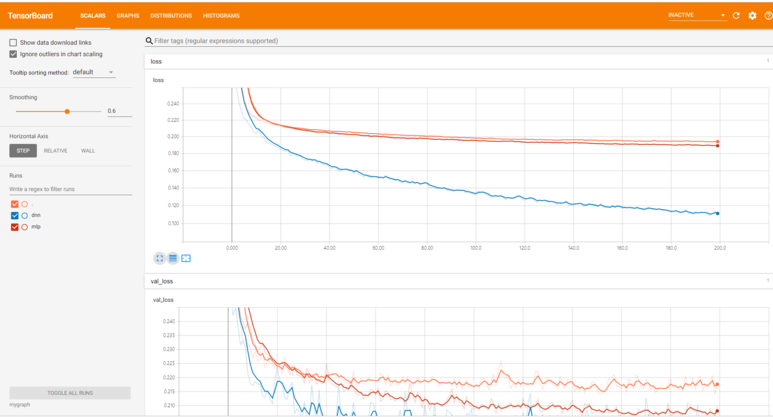
목차 PARTI말 많은 컴퓨터:NLP의 기초 1CHAPTER 1사고 단위:NLP의 개요 31.1자연어-프로그래밍 언어 41.2마법 51.2.1대화하는 기계61.2수학 71.3실제 응용91.4컴퓨터”눈”에서 본 언어111.4.1정 언어 121.4.2정규 표현식131.3 간단한 채팅 봇141.4.4한가지 방법191.5 짧은 초공간 탐험 231.6단어의 순서와 문법 251.7챠쯔토 보트의 자연어 처리 깊은 자연어 처리 파이프 라인 271032 큰 생성기를 사용한 어휘 구축 402.2.1내적502.2 2개의 단어 수집의 중복 측정 512.2.3토큰 개선522.2.4 n-그램을 사용한 어휘 확장 582.5어휘 정규화 662.3감정 분석762.1 VADER-룰 베이스의 감정 분석기782.3.2단순 베이스 모델80요약 84CHAPTER 3말을 잘하는 수학:TF-IDF벡터 853.1단어 수집863.2벡터화923.1 104333.4.5 Okapi BM25 1153.4.6다음 단계 116요약 116CHAPTER 4단어 빈도로 의미를 찾는다:의미 분석1174.1단어 빈도에서 주제 점수로 1194.1.1 TF-IDF벡터와 표제어 추출 1194.2주제 벡터1204.3사고 실험1224.1.4주제를 매겨알고리즘1274.5 LDA분류기1294.2잠재 의미 분석(LSA)1344.1사고 실험의 실현1374.3특이 값 분해 1404464.4 주성분 분석(PCA)1484.4.1 3차원 벡터에 대한 PCA1504.4.2의 끝을 떠나고 다시 NLP에서 1524.4.3PCA을 이용한 문자 메시지 잠재 의미 분석1544.4.4절단된 SVD를 이용한 문자 메시지 잠재 의미 분석1574.5스팸 분류에 대한 LSA의 정밀도1584.5잠재 델리 쿠레 할당(LDiA)1614.1 LDiA의 기초 1624.5.2문자 메시지 코퍼스에 대한 LDiLDALIDALDAI모델 1664.7.1선형 판별 분석(LDA)1774.8주제 벡터의 위력 1794.8.1의미 기반 검색 1814.8.2개선 방안 184요약 184PART II보다 깊은 학습:뉴럴 네트워크 적용 185CHAPTER5신경망 첫걸음:퍼셉트론과 역전파 1875.1신경망의 구성 요소 1885.1.2퍼셉트론 1895.1.2데지탈파ー세프토롱 1905.3편파 단위 1915.4오차 곡면을 뛰어다니고 2075·1·5경사로를 따라서 활강 2085·1·2·5·4경로대로 활강 2085·타ー을 이용한 추론:word2vec활용2176.1의미 기반 쿼리와 비유 2186.1.1비유 질문2196.2단어 벡터2216.2.1벡터 지향적 추론2256.2 . 2 word2vec의 단어 표현 계산2286.2 . 3 gensim . word2vec모듈의 사용법2386.2 . 4나만의 단어 벡터 모델 만들기 2416.5 word2vec-GloVe 2446.6 fastText 2456.7 word2 vec-LSA관계:합성적 신경 회로망 2597.1의미의 학습2617.2툴집 2627.3합성적 신경 회로망 2647.3.1합성적 신경 회로망의 구조 2647.3.2단계사이즈(보폭)2667.3.3필터의 구성 2667.4여백을 메우다2687.5훈련(학습)2707.4다시 텍스트에서 2717.4 . 1땅 강아지 중에 합성적 신경 회로망의 실현:자료 준비 2737.4 . 2콤폿크아우토 2837.4모델의 구조뉴럴 네트워크 2938.1과거를 알순환 뉴럴 네트워크 2968.1.1시간에 대한 역전파3018.1.2무엇을 언제 갱신하는가?3038.1.3정리 3068.1.4여느 때처럼 함정이 있다3078.1.5케라 소스를 이용한 순환 뉴럴 네트워크 구현 3078.2모델의 컴파일 3128.3모델 훈련3158.4초 매개 변수 조정 3168.5예측 3198.5.1상태 유지 3208.2쌍 방향 처리 3218년 5월 3일 순환층 출력의 의미 323 CHAPTER 9장단기 기억망(LSTM망)을 이용한 기억 유지 개선 3259.1장단·단기 기억망(LSTM)329M에 대한 3 3459.1.6말 문이 열린 신경망 3529.1.7구체적인 사례 하나 3549.1.8무엇을 말하는 거냐?3639.1.9 다른 종류의 기억 수단 3639.1.10더 깊이 들어 364요약 366CHAPTER 10순차적으로 열 대 차례차례 줄 모델과 주의 메커니즘36710.1부호기-복호화기 구조 36810.1.1사고 벡터의 복호화 36910.2유사한 구조37110.3대화 생성을 위한 순차적으로 열 대 차례차례 줄 모델 37310.4 LSTM복습 37410.2차례차례 줄-차례차례 줄-차례차례 줄 NLP파이프 라인 구축 37510.2.1차례로 줄 훈련을 위한 자료 집합 준비375102네트워크 조립 38010.3시퀀셜열-시퀀셜열 생성 38110.3.1출력 시퀀셜열 생성 38110.4시퀀셜 줄 뉴럴 네트워크를 이용한 채팅 봇 구축 38310.4.2문자 사전 구축 38410.4.3원 핫 부호화 훈련 세트 생성 38510.4.4시퀀셜열-시퀀셜열 생성을 위한 모델 설정 38710.4.6시퀀셜열 생성(예측)38710.4.7응답 글 작성 및 출력 38810905배팅을 사용했다393요약 395 PART III응용:실제의 NLP문제 397CHAPTER 11정보 추출:개체나 인식과 질의 응답 39911.1개체 이름과 개체 관계 39911.1지식 베이스 40011.2정보 추출 40311.2정규 패턴 40411.2.1정규 표현식4051 1.2기계 학습 특징 추출한 정보 추출 40611.3추출해야 할 정보40811.3 GPS좌표 추출 40811.4날짜 추출 415 11.4인체 정규화물 4. 한명(‘!?’)만으로는 안 되는 이유42411.4.7정규 표현식을 이용한 문장 분할42611.5실제 용도 428요약 429CHAPTER 12챠쯔토 보트(대화 엔진) 만들기43112.1대화 능력43212.1현대적 접근 43412.1.2혼합 접근 44112.2패턴 맞춤 접근 44112.2 AIML을 이용한 패턴 맞춤형 채팅 봇 실장 44312.2패턴 맞춤의 그래프 시각화45012.3근거화45112.4정보 검색45112.4 12.4 12PIA에 관한 대화46412.5.2각 어프로치의 장단점 46612.6사륜 구동 46712.6.1채팅 봇 프레임워크 Will 46812.7설계 과정 46912.8요령과 편법47312.8.1예측 가능한 답이 나올 질문을 던져47312.8.3마지막 대책은 검색 47412.8.4흥미 유지475 12.5연 만들기475 12.8.6감정을 넣고 475 12.9실제 응용 분야 476요약 477CHER, 병렬 처리 1328313.2.3 Annoy를 이용한 고급 색인화48513.2.4근사 색인이 꼭 필요한가?49013.2.5실제 수치의 색인화:이산화 49113.3상수 RAM알고리즘 49213.3.1gensim49213.3.2그래프 계산 49313.4NLP계산 병렬화 49413.4.1GPU을 사용한 NLP모델 훈련 49513.4.2임대라 구입 49613.4.3GPU대여 옵션 49813.5모델 훈련의 메모리 요구량을 줄이고 49813.6TensorBoard를 사용한 모델 성능 평가 50113

책에서 P.45단어의 이러한 벡터 표현과 문서의 테이블 표현이 가진 하나의 장점은 어떤 정보도 소실하지 않는다는 점이다.각 줄이 어떤 단어에 대응하느냐에 관한 정보만 유지하면 이런 원 핫 벡터의 테이블에서 원본 문서를 복원할 수 있다.그리고 이런 복원 과정은 100%정확하다.비록 현재의 토큰 생성기가 우리가 유용하다고 생각하지 않나!!!상세 P.109 간단한 검색 엔진은 바로 이 TF-IDF수치 하나에 근거하고 있다.이 수치를 통해서 우리는 텍스트(문자열)처리의 세계에서 수치 연산의 세계에 확실하게 이행하게 됐다.다음 절에서는 이 수치에서 할 수 있는 계산을 본다.실제로 여러분이 TF-IDF계산을 구현하는 코드를 실제로 작성하는 것은 거의 없을 것이다.선형 대수를 몰라도… 그렇긴 더 보면 P.130LDA모델의 “훈련”에 필요한 것은 아무리 부류의 두 중심을 잇는 직선을 찾는다.이번 사례의 분류기는 주어진 단문 문자(SMS)메시지가 스팸 여부를 분류한다.즉, 이진 부류는 “스팸”-“비스팜”이다.LDA은 지도 학습에 속하므로, 훈련용 문자(SMS)메시지에 분류 이름(class label)을 달아 두면…이래봬도 이어 P.153이런 과대 적합성은 NLP의 고질적이다.사람들의 다양한 어법과 어휘를 포함한 응용 분야에 맞는 적절한 분류 이름이 붙은 자연 언어 자료 세트를 찾기는 쉽지 않다.실제로 나는 스패머가 고안할 수 있는 모든 스팸 단어와 비스팜 단어를 포함한 거대한 문자 메시지 데이터 베이스를 손에 넣지 못 했다.그런 자료 집합을 만들어 낼 수 있지 않나!!!상세 P.293합성적 필터는 인접한 단어에서 특정 패턴을 검출한다.그리고 단어의 위치가 바뀌되 조작적 신경 회로망의 출력은 크게 영향을 받지 않는다.중요한 점은 서로 근처에 있는 개념이 합성적 신경 회로망에 큰 영향을 미친다는 것이다.더 넓은 시야에서 텍스트를 바라보고, 보다 긴 시간 구간에서 단어 간의 관계를 파악하고 싶다…더 보기
책에서 P.45 단어의 이러한 벡터 표현과 문서 테이블 표현이 갖는 하나의 장점은 어떠한 정보도 소실되지 않는다는 점이다. 각 열이 어떤 단어에 대응하는지에 대한 정보만 유지하면 이러한 원핫 벡터 테이블에서 원래 문서를 복원할 수 있다. 그리고 이런 복원 과정은 100% 정확하다. 비록 현재 토큰제너레이터가 우리가 유용하다고 생각해… 상세 P.109 간단한 검색엔진은 바로 이 TF-IDF 수치 하나를 기반으로 한다. 이 수치를 통해 우리는 텍스트(문자열) 처리의 세계에서 수치 연산의 세계로 확실히 이행하게 되었다. 다음 절부터는 이 수치로 할 수 있는 계산을 살펴본다. 사실 여러분이 TF-IDF 계산을 구현하는 코드를 실제로 만드는 일은 거의 없을 것이다. 선형대수를 몰라도… 더 보는 P.130LDA 모델의 ‘훈련’에 필요한 것은 이진 부류의 두 무게중심을 잇는 직선을 찾는 것이다. 이번 예의 분류기는 주어진 단문문자(SMS) 메시지의 스팸 여부를 분류한다. 즉, 이진 부류는 「스팸」 대 「비스팜」이다. LDA는 지도학습에 속하므로 훈련용 문자(SMS) 메시지에 분류명(class label)을 붙여두면…. 게다가 P.153 이런 과대적합은 NLP의 고질적인 문제다. 사람들의 다양한 어법과 어휘를 포함해 응용 분야에 맞는 적절한 분류명이 붙은 자연어 자료 세트를 찾기는 쉽지 않다. 사실 나는 스패머가 고안할 수 있는 모든 스팸 단어와 비스팜 단어를 포함하는 거대한 문자 메시지 데이터베이스를 구할 수 없었다. 그런 자료 집합을 만들어 낼 수 있는… 상세 P.293 합성곱 필터는 인접한 단어에서 특정 패턴을 검출한다. 그리고 단어의 위치가 조금 바뀌어도 합성곱 신경망의 출력은 크게 영향을 받지 않는다. 중요한 점은 서로 가까이 있는 개념이 합성곱 신경망에 큰 영향을 준다는 것이다. 하지만 더 넓은 시야로 텍스트를 바라보고, 더 긴 시간 구간에서 단어 간의 관계를 파악하고 싶다…더 보기

추천사 NLP시스템의 내부 작동 방식을 이해하는 것은 물론 여러분 스스로 알고리즘과 모델을 만드는데 필요한 이론과 실무 지식을 배운다.-Dr. 아우오은그리피옹, 요즘 쓰이는 파이썬 NLP도구를 잘 개괄하다.저의 NLP프로젝트별로 이 책을 지니고 다닐 것이다.강한 추천하라!-토니…마리 렌(노스 이스턴대(시애틀)NLP를 시작하는 사람을 위한 직관적인 지침서!NLP를 매우 실용적으로 배울 수 있는 프로그래밍 예로 가득하다.-토마소·테오 후이 리우(Adobe Systems)
추천문 NLP 시스템의 내부 작동 방식을 이해하는 것은 물론, 여러분 스스로 알고리즘과 모델을 만드는 데 필요한 이론과 실무 지식도 배운다. – Dr. 어원그리피온, 최근 사용되고 있는 파이썬 NLP 툴을 잘 개괄한다. 내 NLP 프로젝트마다 이 책을 달고 다닐 거야. 강력 추천한다! – 토니 멀린(노스이스턴대학교(시애틀)) NLP를 시작하는 사람들을 위한 직관적인 지침서! NLP를 매우 실용적으로 배울 수 있는 프로그래밍 예시들로 가득하다. – 토마소 테오필리(Adobe Systems))

추천문 NLP 시스템의 내부 작동 방식을 이해하는 것은 물론, 여러분 스스로 알고리즘과 모델을 만드는 데 필요한 이론과 실무 지식도 배운다. – Dr. 어원그리피온, 최근 사용되고 있는 파이썬 NLP 툴을 잘 개괄한다. 내 NLP 프로젝트마다 이 책을 달고 다닐 거야. 강력 추천한다! – 토니 멀린(노스이스턴대학교(시애틀)) NLP를 시작하는 사람들을 위한 직관적인 지침서! NLP를 매우 실용적으로 배울 수 있는 프로그래밍 예시들로 가득하다. – 토마소 테오필리(Adobe Systems))

출판사 제공본 소개

파이썬과 다양한 AI패키지로 만드는 수준 높은 예!최신의 NLP제품과 서비스 개발을 위한 실용주의적 가이드!최근 심층 학습(딥-러닝)기술이 발전하면서 애플리케이션이 매우 정확하게 텍스트와 음성을 인식하게 되었다.또 새로운 기술과 Keras나 TensorFlow 같은 편리한 도구 덕분에 지금은 고품질 NLP(자연어 처리)애플리케이션을 이전보다 쉽게 만들어 낼 수 있다.이 책은 사람의 언어를 읽고 해석할 수 있는 프로그램을 만들려는 모든 개발자를 위한 지침서다.본서에서는, 금방 쓴 파이썬 패키지를 이용하여 텍스트의 의미를 파악하는 응하고 반응하는 채팅 봇을 구축한다.또 전통적인 NLP접근은 물론, 보다 최근의 심층 학습 알고리즘과 텍스트 생성 방법을 동원하고 날짜와 이름 추출, 텍스트 작성, 비정형 질문에 대한 응답 등 많은 실질적인 NLP문제를 해결한다.본서의 주요 내용 ■Keras, TensorFlow, gensim, scikit-learn의 사용법 ■ NLP의 룰 베이스 접근과 자료 기반 접근 ■ 규모 확장이 용이한 NLP관